Group Streaming Data by Key in Dataflow
Dataflow is a managed service for Apache Beam on GCP. It can apply the same data transformation on both batch and streaming data. Apache Beam implements the map-reduce model where each data element can be processed individually on multiple workers then group and aggregate to get desired result.
A typical use case for dataflow on GCP is to transfer large amount of data between different storage services and / or message queues while apply data transformation.
PoC Overview
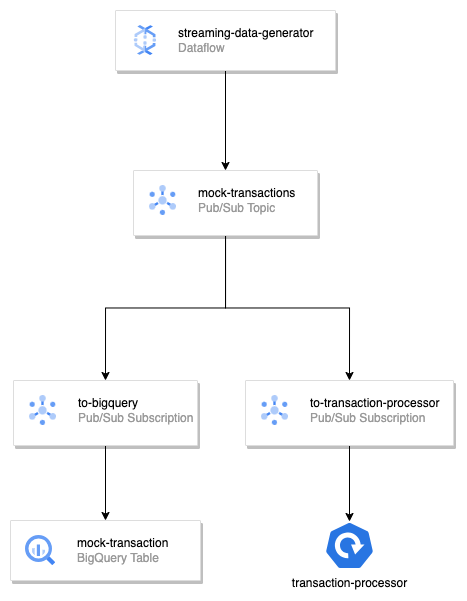
In this PoC, a dataflow job starts by generating mock transaction events then apply window and groupByKey transformation before sending the aggregated message to a PubSub topic. In the PubSub topic, I added a BigQuery subscription for messages to fly directly to BigQuery. This can be used for monitoring data and creating backup. If another message processor exists, it can pick up the messages from another dedicated subscription.
Code Walkthrough
Below is the pipeline code. All transformations are packed with Apache Beam. There can be adjustment regarding the window function, watermark and trigger. And it depends on what timestamp attribute comes with the input. Beam Programming Guide is a good place to start to get more information on Windowing.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// create pipeline object
PipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(PipelineOptions.class);
Pipeline pipeline = Pipeline.create(options);
// generate sequence with certain rate and output random test data
PCollection<KV<String, String>> input = pipeline.apply("generate sequence with rate", GenerateSequence
.from(0)
.withRate(2000, Duration.standardSeconds(1)) // simulate 2000 messages per second
.withTimestampFn((Long n) -> new Instant(System.currentTimeMillis()))) // each element has a timestamp attribute of current system time which is used in the window function later
.apply("generate mock data", ParDo.of(new RandomDataGeneratorFn())); // generate mock transaction events per sequence as a key value pair where customer name is key and transaction event is value
// apply fixed window of 10 seconds
PCollection<KV<String, String>> windowedTrans = input.apply("Divide into Fixed Window",
Window.into(FixedWindows.of(Duration.standardSeconds(10))));
// group transaction by key which is customer name
PCollection<KV<String, Iterable<String>>> groupedTrans = windowedTrans.apply("Group by customer",
GroupByKey.create());
// construct message by putting grouped transaction value into an array
PCollection<String> aggregatedTrans = groupedTrans.apply("Aggregate to a single message",
ParDo.of(new DoFn<KV<String, Iterable<String>>, String>() {
@ProcessElement
public void processElement(ProcessContext c) {
JSONArray message = new JSONArray("[]");
message.putAll(c.element().getValue());
c.output(message.toString());
}
}));
// send message to pubsub
aggregatedTrans.apply("Publish to PubSub", PubsubIO.writeStrings().to("projects/second-flame-396801/topics/mock-transactions"));
pipeline.run();
Here is the mock transaction generator code. It picks a random customer from a predefined list then add in random amount and an UUID.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
static class RandomDataGeneratorFn extends DoFn<Object, KV<String, String>> {
private static final String[] customers = {
"alex",
"bob",
"charlie",
"dave",
"ethan",
"frank"
};
@ProcessElement
public void processElement(ProcessContext c) {
String customer = getRandomCustomer();
Integer amount = getRandomAmount();
JSONObject sampleTransaction = new JSONObject();
sampleTransaction.put("transactionUUID", UUID.randomUUID());
sampleTransaction.put("customer", customer);
sampleTransaction.put("amount", amount);
sampleTransaction.put("timestamp", c.timestamp().toString());
c.output(KV.of(customer, sampleTransaction.toString()));
}
private String getRandomCustomer() {
int rnd = new Random().nextInt(customers.length);
return customers[rnd];
}
private Integer getRandomAmount() {
return new Random().nextInt(500);
}
}
Live Action
After creating mentioned PubSub and BigQuery resources, deploying to dataflow can trigger from local:
1
2
3
4
5
6
mvn -Pdataflow-runner compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.StreamingDataGenerator \
-Dexec.args="--project=second-flame-396801 \
--gcpTempLocation=gs://second_flame_396801_dataflow_temp/temp/ \
--runner=DataflowRunner \
--region=australia-southeast1"
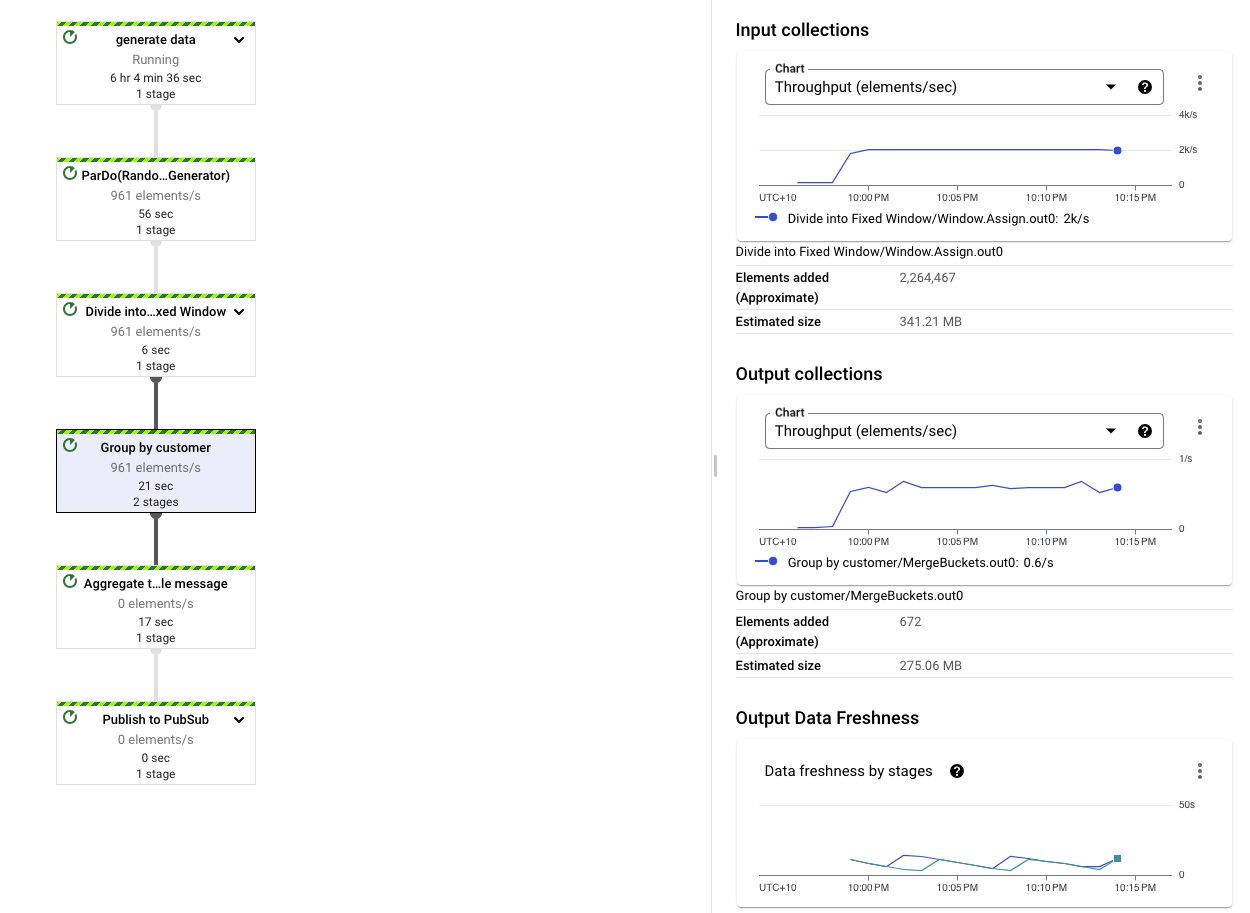
Then a streaming job is created. By looking at group by customer step, messages are going in at 2000 elements per second and after aggregation, only 0.6 elements per second is going out, which makes sense given there are only 6 mock customer in the generator function. If the mock generator could read a bigger predefined test customer table as a side input, this simulation can be more realistic.
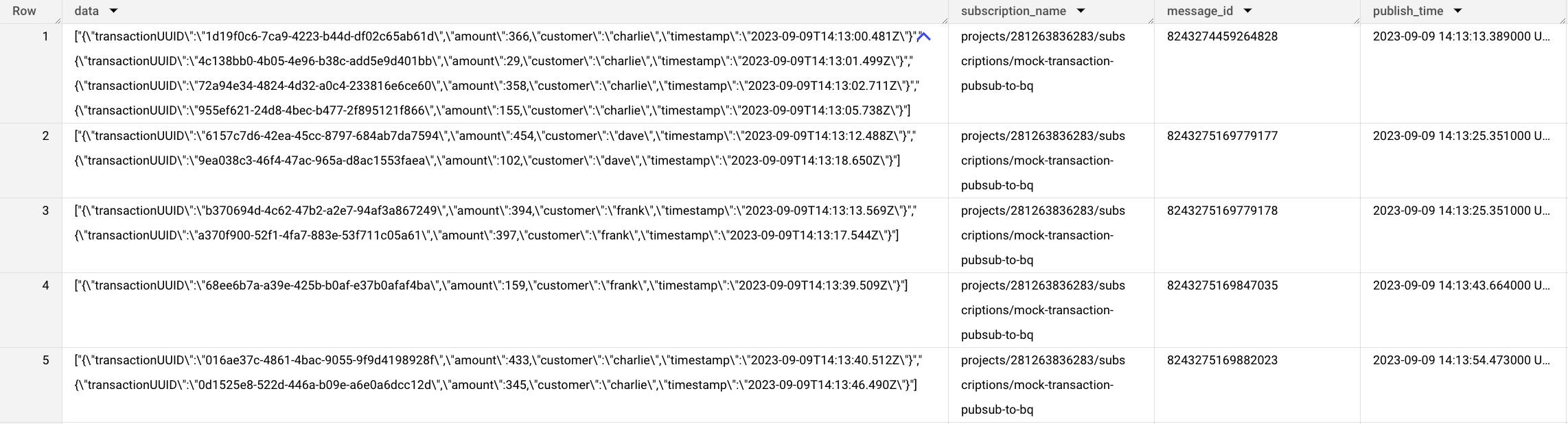
On the consumer end, BigQuery subscription writes event data, subscription name, message id and publish time. Each row represents one pubsub message where transactions are grouped by customer over a 10 second window.